
Acoustic Data Augmentation
Introduction
Large-scale deep learning systems require an abundance of labeled training datasets to achieve good and robust performance, but it may not always be feasible. Data augmentation has been proposed as an effective technique to increase both the amount and diversity of data by randomly augmenting it.
In vision systems, some image processing operations, such as translation, rescaling, rotation, or color normalization, do not affect the class label of the object in the image but are yet able to create new related data examples. Augmenting datasets by transforming inputs in a way that does not change the label is crucial.
The same strategy could be applied to augment acoustic databases. Speech synthesis schemes, such as noise superposition, vocal tract length perturbation (VTLP), speed perturbation, and audio reconstruction are investigated.
Another widely used approach to expand training data is semi-supervised learning annotation. It can adopt massive quantities of new data with minimum human annotation effort. This approach can be used in different areas including acoustic data augmentation.
Data augmentation has been highly effective in improving the performance of deep learning in computer vision. This has also been shown to improve automatic speech recognition (ASR) systems.
At Businessolver, we reviewed current literature on this topic to build acoustic data augmentation approaches for training speech recognition systems. Based on the findings, an overview of existing approaches including semi-supervised learning annotation, and various synthetic data augmentation schemas is presented in this article.
Semi-Supervised Learning Annotation
Traditionally, acoustic model development for ASR systems relies on the availability of large amounts of supervised data manually transcribed by humans. Even for fine-tuning, to achieve improved accuracy, large volumes of high-quality annotated data are required. Unfortunately, manual transcription of large data sets is both time-consuming and expensive, requiring trained human annotators and substantial amounts of supervision.
The unsupervised data refers to data that could have incorrect transcriptions. The rapid increase in the amount of multimedia content on the Internet makes it feasible to collect vast amounts of unsupervised acoustic datasets covering all demographic variety and noise conditions.
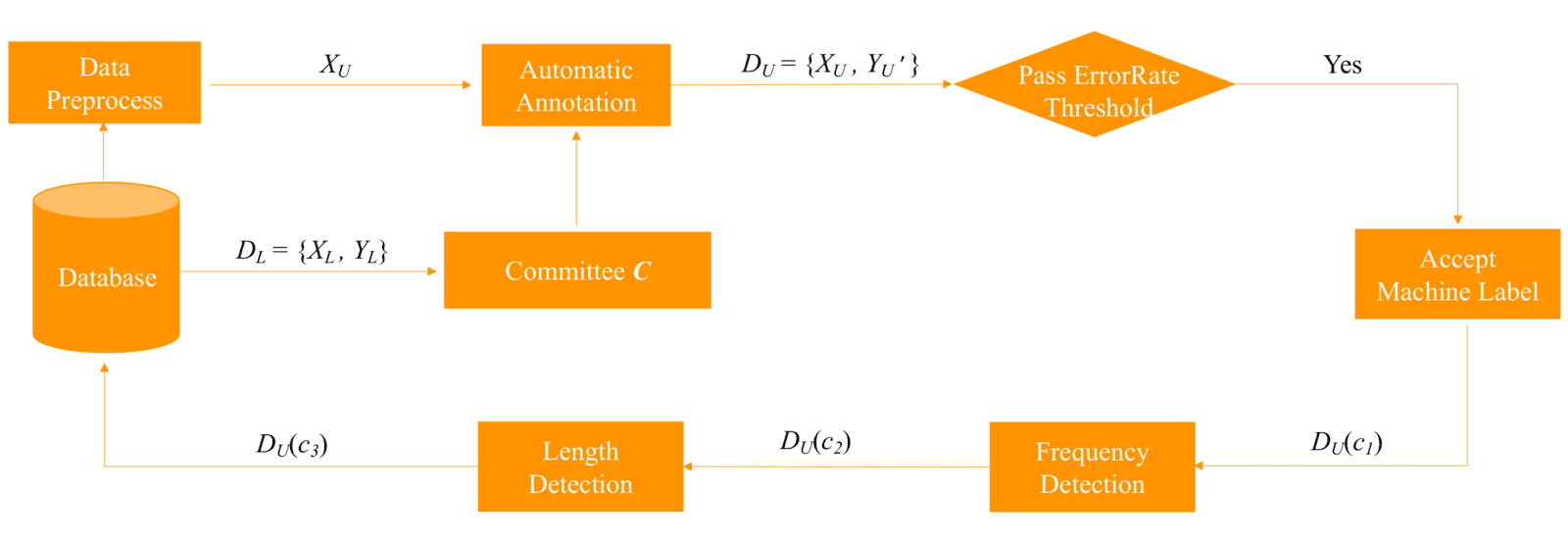
Rather than relying on small, supervised training sets, semi-supervised annotation is proposed to bootstrap larger datasets, and reduce system development cost. Semi-supervised annotation can be achieved with different components. Figure 1 below illustrates the main components of semi-supervised annotation process in ASR system that can be implemented to bootstrap new data collection.
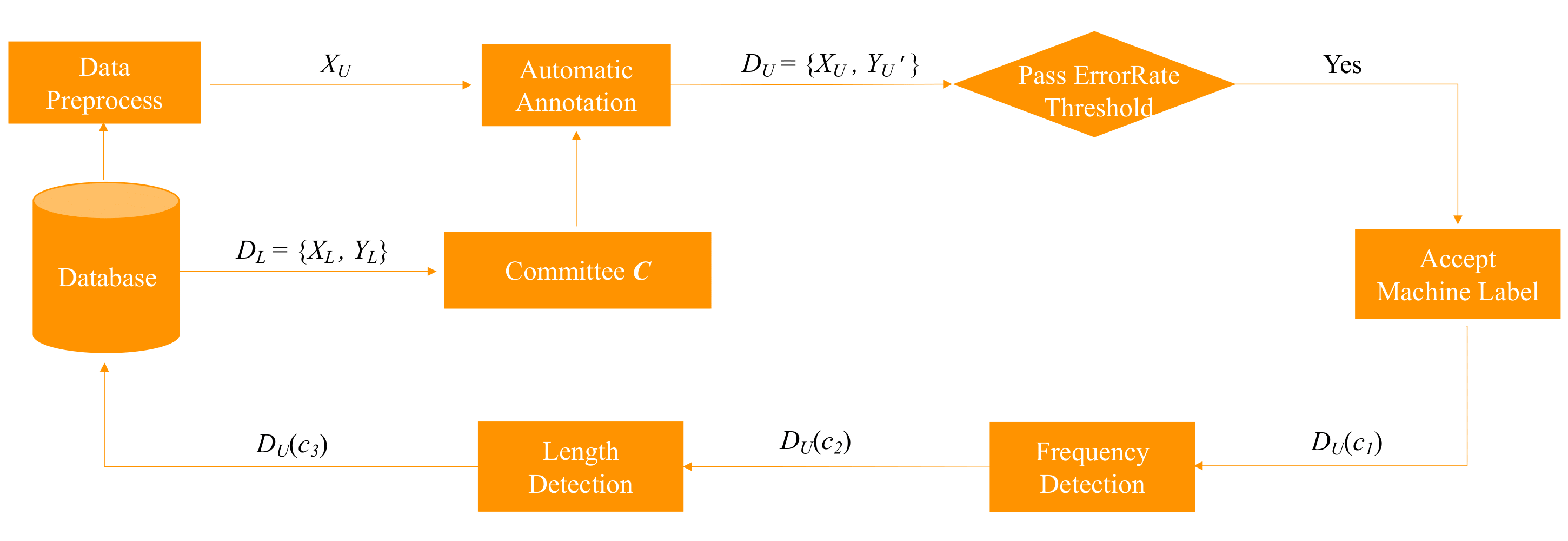
Figure 1: Main components of the semi-supervised annotation process.
The process takes as input a set of labeled examples $D_{L}$ and produces committee recognizers $C$ which are used to generate the rough transcriptions $D_U^{prime}$ for a larger set of unlabeled examples $D_{U}$. After a few filters, a relatively small set of newly labeled data $D_U^{prime}(c3)$ which are adopted as part of new labeled data $D_{L}$ to retrain the system. The process is cyclical and iterative as every step is repeated to continuously improve the accuracy of the system and achieve a successful algorithm.
Committee recognizers $C$ can include offline recognizers trained using labeled audio data $D_{L}$ or existing speech recognizer APIs. At Businessolver, we fine-tuned Deepspeech and Wav2Vec models based on $D_{L}$. We then employ the fine-tuned models along with AWS and Google Recognizer APIs to form committee recognizers $C$ which automatically generate rough transcriptions $D_{U}^prime$ for a massive amount of unannotated audio data. Utterances $D_U^{prime}(c1)$ meeting the confidence threshold are accepted with corresponding labels.
However, selecting utterances by confidence score alone may lead to a disproportionate training dataset with frequent tokens overrepresented. To alleviate this problem, frequency detection can be implemented as one component of the pipeline. A threshold is determined to limit the number of the similar utterances which contain a set of the same key words in the dataset and make sure the filtered dataset $D_U^{prime}(c2)$ is diverse and has a larger vocabulary.
Another constraint on the data selection is the audio duration or character lengths. Short audios usually do not contain any useful information. Long audios have much higher cost during training. At Businessolver, we only take audios with duration of 1 to 15 seconds as training data.
After transcription, utterances with too short or too long character lengths are also removed. At Businessolver, we keep utterance character lengths between 3 and 150. The reconstruction section below discusses how to reconstruct new audio segments using utterances that are either too short or too long.
The semi-supervised annotation approach directly relies on the transcripts generated by speech recognizers and the thresholds determined by the experiment to cull sufficient quality data without any reliance on manual transcription.
Synthetic Data
Data synthesis is one popular approach to expand the potential training data even further.
The synthesized data can be obtained by perturbing the original data in a certain way. One major advantage of synthesized data is that, like the unsupervised case, it is feasible to collect vast amounts of such data. Furthermore, different from the unsupervised case, the correctness of the corresponding transcripts is generally guaranteed. A major disadvantage of synthetic data is its quality.
There are numerous techniques for data perturbation. Options include simple noise superposition, simulating changes to the vocal tract length, simulating changes to the speed rate, and audio reconstruction including concatenative and splitting.
Variable Noise Superposition
Superimposing clean audio $x(t)$ with a noisy audio $sigma(i)$ can synthesize noisy audio $ hat{x} (t) = x(t) + sigma(t)$.
Although the original data may contain some intrinsic noise, corrupting clean training speech with variable noise can increase variety of noise and improve the robustness of the speech recognizer against noisy speech.
Note, the noisy audio $sigma(t)$ needs to be unique, since the acoustic model may memorize
repeated noise and ‘subtract’ it out of the synthetic data. The best proportion of noise augmentation utterances are dataset specific. Too much noise augmentation can lead to worse results.
There are many ways to do noise superposition in Python. The following code used the overlay function in pydub library.
Code:
from pydub import AudioSegment noise_audio = AudioSegment.from_file() wav_audio = AudioSegment.from_file() augmented_audio = wav_audio.overlay(noise_audio - i, gain_during_overlay=j). # i, j are used to adjust the volume of the noise audio and clean audio.
Results
The seed audio:
Noise superposition augmented audio:
Vocal Tract Length Perturbation (VTLP)
One way of perturbing data is to transform spectrograms, using a randomly generated warp factor $aleph$ to warp the frequency dimension, such that a frequency $f$ is mapped to a new frequency $f{prime }$ via a function of $aleph$. This transformation is mostly imperceptible to human ears, however, the difference can be seen when we plot power vs frequency in Figure 2.
A random warp factor $aleph$ is generated for each audio. A boundary frequency $F$ which covers the significant formants is chosen. The new augmented audio has new frequency $f{prime }= f aleph$ for $f <F$.
Traditionally, the warp factor is assumed to lie between 0.8 and 1.2. Since the goal is to augment the training database and high warps or low warps may generate unrealistic distortions, a smaller range of 0.9 and 1.1 is recommended for speech recognition
Python package ‘nlpaug’ contains a function ‘VtlpAug’ to implement the augmentation. It is not easy to hear the difference between the seed audio and augmented audio, but the power and frequency plot shows the difference. The boundary frequency for the example audio is around 12(K Hz).
Code:
import nlpaug.augmenter.audio as naa aug = naa.VtlpAug(sampling_rate=sr, factor=(0.9, 1.1)) audio,_=librosa.load(w,sr) augmented_audio = aug.augment(audio)
VTLP augmented Audio:
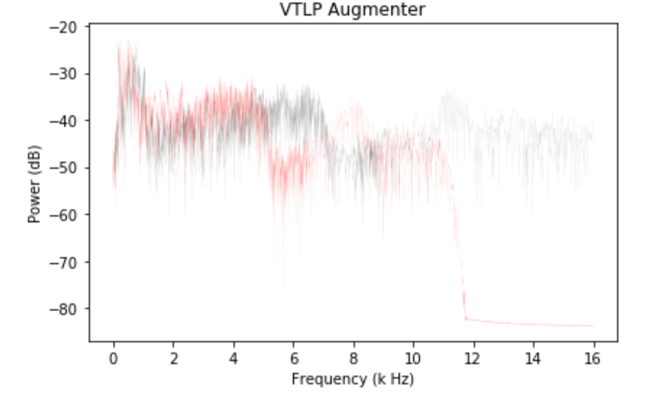
Figure 2: power and frequency plot for VTLP augmented audio. Black line: original audio vs Red line: augmented audio.
Speed Perturbation
One proposed data augmentation technique is to change the speed rate of the audio. It is easy to adopt and has a low implementation cost. [4] shows speed perturbation give more WER improvement than VTLP method.
Multiple versions of the original audio can be produced with different warping factors {$alpha$_i}, which usually ranged between 0.9 and 1.1. Given an audio x(t), speed perturbation by a factor α gives a new audio x(αt) which creates a change in the duration and the number of frames.
Code:
import nlpaug.augmenter.audio as naa aug = naa.SpeedAug(factor= (0.9, 1.1)) audio,_=librosa.load(w,sr) augmented_audio = aug.augment(audio)
Results
Figure 3: Waveplot of the original audio (orange) VS speed perturbation augmented audio (red)
Reconstruction
Rather than perturbing existing data it is possible to artificially generate new examples using speech synthesis approaches, such as concatenative or splitting.
The concatenative approach attempts to synthesize speech by concatenating existing audio segments into long sentences. It can be applied for training data with insufficient number of long sentences which causes poor performance in the long sentence translation.
In practice, most acoustic model training procedures expect that the training data comes in the form of relatively short utterances with associated transcripts, since long utterances have higher cost than short utterances in speech recognition. However, some of the internal datasets ranged from several minutes to more than hours with noisy transcriptions. The length of this data makes it impractical to train a sequence model.
The splitting approach can generate a training set with shorter utterances and few erroneous transcriptions. It splits long audio into shorter segments, aligns the segments with the corresponding transcripts, and filters out segments that have a high likelihood of inaccurate aligned transcripts.
Summary
Semi-supervised learning annotation can construct large high quality unsupervised sets to train ASR systems. A variety of schemas can be easily used to generate synthetic data, including but not limited to noise superposition, vocal tract length perturbation (VTLP), speed perturbation, and audio reconstruction. It should be noted that the synthetic data generated via perturbations can only create examples of the same phoneme contexts as the seed audios. In low resource settings, semi-supervised learning annotation would be useful since it can adopt examples of different phoneme contexts.
The best augmentation strategies are usually dataset specific. Augmenting data in an appropriate way has been shown to give better performance and improved robustness in the ASR system.
Reinforcement Learning can be used as a search algorithm to find the best choices of the operations which yields the best validation accuracy.
Reference:
- https://aclanthology.org/2020.ecnlp-1.4/
- https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43230.pdf
- https://arxiv.org/abs/1512.02595
- https://www.danielpovey.com/files/2015_interspeech_augmentation.pdf
- https://www.cs.toronto.edu/~ndjaitly/jaitly-icml13.pdf
- https://mi.eng.cam.ac.uk/~ar527/ragni_is2014a.pdf
- https://nlpaug.readthedocs.io/en/latest/index.html